2013-11-21 :-(
_ 午後
1300 コード書いTARI
_ [スレッド][スケジューリング][スケジューラ][NetBSD][翻訳]Thread scheduling and related interfaces in NetBSD 5.0 (PDF) NetBSD 5.0 でのスレッドスケジューリングと関連するインターフェース
Introduction はじめに
A lot of new features were implemented in the NetBSD 5.0 release, and many improvements were made in the areas of scheduling, threading and symmetric multiprocessing (SMP). Like other modern UNIX-like operating systems, NetBSD supports traditional processes created by fork(2) and native POSIX threads (pthreads). Prior to the 5.0 release, user threading on NetBSD was implemented using a mechanism called scheduler activations (SA). The SA implementation was complicated, scaled poorly on multiprocessor systems and had no support for real-time applications. In NetBSD 5.0 these deficiencies have been addressed by replacing SA with an entirely new, scalable 1:1 threading model. In a 1:1 model each user thread (pthread) has a kernel thread called a light-weight process (LWP). Inside the kernel, both processes and threads are implemented as LWPs, and are served the same by the scheduler, as in Solaris, and other systems. In this article, we will review the scheduling of threads, related application programming interfaces, and utilities in the NetBSD operating system. Since the focus of this article is to introduce readers to new interfaces, we will not go into the details of implementations inside the kernel.
NetBSD 5.0 release にはたくさんの新機能が実装された。たくさんの改良がスケジューリング、スレッディング、対称型マルチプロセッシング( SMP )の分野について実装された。他のモダンな UNIX 風オペレーティングシステムのように、NetBSD は fork(2) によって生成された伝統的なプロセスや Native POSIX Thread (pthreads) に対応した。5.0 release 以前は、NetBSD でのユーザースレッディングは scheduler activations (SA) と呼ばれる機構を使って実装された。SA 実装は複雑であり、マルチプロセッサシステムではスケールが貧弱で、リアルタイムアプリケーションに未対応だった。NetBSD 5.0 ではこれらの欠点を完全に新規な SA に置き換えた。SA はスケーラブルな 1:1 スレッディングモデルである。1:1 モデルにおいて、各ユーザースレッド (pthread) は、ライトウェイトプロセス (LWP) と呼ばれるカーネルスレッドを持つ。Solari やその他のシステムでは、カーネル内においてプロセスとスレッドは LWP として実装され、スケジューラーからは同じように運用される{ served }。この論文では、スレッドのスケジューリング、アプリケーションプログラミングインターフェース、そして NetBSD オペレーティングシステムでのユーティリティについて再考{ review }する。この論文は新しいインターフェースの導入部なので、カーネル内の実装の詳細については触れない。
Real-time and scheduling classes リアルタイムとスケジューリングクラス
A real-time system is a predictable system which aims to meet certain time constraints (deadlines). Failure to meet these time constraints usually indicates hardware failure. Systems can be classiffied as either hard or soft real-time systems. Hard real-time systems shall meet the requirements unconditionally. That is, their predictability is deterministic. Soft real-time systems are not deterministic; they can tolerate some latencies, but their objective is to minimize them. NetBSD 5.0 provides soft real-time extensions.
リアルタイムシステムは予測可能なシステムである。制限された時間内(デッドライン)に完了する。これらの制限時間が満たされない場合、通常はハードウェア故障を意味する。システムはハードまたはソフトリアルタイムシステムとして分類される。ハードリアルタイムシステムは、絶対に要求を満たすべきである。すなわち、それらの予測可能性は決定的である。ソフトリアルタイムシステムは非決定的である。いくらかのレイテンシが許されるが、最小となることを目標とする。NetBSD 5.0 はソフトリアルタイム拡張を提供する。
According to the POSIX standard, at least the following three scheduling policies (classes) should be provided to support the POSIX real-time scheduling extensions:
POSIX 標準によると、POSIX リアルタイムスケジューリング拡張に対応するには、少なくとも以下の 3 つのスケジューリングポリシー (クラス) を提供すべきである。
- SCHED OTHER: Time-sharing (TS) scheduling policy, the default policy in NetBSD.
- SCHED FIFO: First in, first out (FIFO) scheduling policy.
- SCHED RR: Round-robin scheduling policy.
- SCHED OTHER: タイムシェアリング (TS) スケジューリングポリシー。NetBSD の既定のポリシー
- SCHED FIFO: 先入れ先出し (FIFO) スケジューリングポリシー
- SCHED RR: ラウンドロビンスケジューリングポリシー
The standard defines algorithms for the real-time SCHED FIFO and SCHED RR policies, and leaves SCHED OTHER as an implementation-defned policy; that is, it is specific to the operating system. All three policies are provided in NetBSD 5.0 and fit in the following in-kernel priority model:
POSIX 標準はリアルタイム SCHED FIFO と SCHED RR ポリシーのアルゴリズムを定義しており、SCHED OTHER は実装定義ポリシーとする。つまりオペレーティングシステム固有である。NetBSD 5.0 では 3 つすべてのポリシーを提供し、以下のカーネル内優先度モデルを適用する:
| Kernel (RT) | 192 .. 223 | 32 levels | Software interrupts. |
| User (RT) | 128 .. 191 | 64 levels | Real-time user threads (SCHED FIFO and SCHED RR policies). |
| Kernel threads | 96 .. 128 32 levels | Internal kernel threads (kthreads), used by the I/O, VM and other kernel subsystems. | |
| Kernel | 64 .. 95 32 levels | Kernel priority for user processes/threads, which is tem-porarily given when process/thread enters the kernel-space and blocks (sleeps). | |
| User (TS) | 0 .. 63 | 64 levels | Time-sharing range, where user processes/threads runby default (SCHED OTHER policy). |
| Kernel (RT) | 192 .. 223 | 32 levels | ソフトウェア割り込み |
| User (RT) | 128 .. 191 | 64 levels | リアルタイムユーザースレッド (SCHED FIFO と SCHED RR ポリシー)。 |
| Kernel threads | 96 .. 128 32 levels | カーネル内スレッド (kthreads), I/O、VM、他カーネルサブシステムから利用される。 | |
| Kernel | 64 .. 95 32 levels | ユーザープロセス/スレッドのカーネル優先度。プロセス/スレッドがカーネル空間に入るりブロック( sleep )したときの一時的なもの。 | |
| User (TS) | 0 .. 63 | 64 levels | タイムシェアリングの範囲。ユーザープロセス/スレッドの既定動作 (SCHED OTHER policy)。 |
These priorities are only used in the kernel, and internals are revealed only to provide a better understanding of the scheduling system as a whole. The POSIX standard requires at least 32 priority levels for the real-time scheduling policies. NetBSD 5.0 provides 64 priority levels, which are internally mapped to the appropriate kernel range shown above. It is not portable to depend on any of these constants, therefore using them is strongly discouraged. Applications should determine the priority range of the specific policy using the following functions defined by the standard:
これらの優先度はカーネル内でのみ使用され、内部についてはスケジューリングシステム全体を理解しやすい程度にする。POSIX 標準はリアルタイムスケジューリングポリシーに少なくとも 32 優先度レベルを要求する。NetBSD 5.0 は 64 優先度レベルを提供する。これは上記のカーネル範囲内に対応する。これらの内容のすべての依存性については可搬性が無いので、それらを使うことはとてもしんどい。アプリケーションは、標準によって定義された以下の関数を使うにあたって、ポリシー固有の範囲での優先度を決定すべきである:
int sched_get_priority_min(int policy); int sched_get_priority_max(int policy);
In NetBSD, the run queue of LWPs is implemented as a traditional multi-level feedback queue, like in many UNIX-like operating systems. The default SCHED OTHER policy is either the original 4.4BSD scheduling or traditional UNIX time-sharing approach like in Solaris, depending on which scheduler is chosen. It can be chosen using the SCHED 4BSD or SCHED M2 kernel options. One of the main objectives of a time-sharing queue is to give a priority boost for I/O bound threads (which allows the kernel to provide good response times for interactive tasks) and ensure fairness. Each LWP has a priority and time-quantum (amount of time allocated by the scheduler to run on the CPU). In a time-sharing queue, both values are dynamically calculated by the scheduler.
NetBSD での LWP のランキューは、たくさんの UNIX 風オペレーティングシステムのように、伝統的な多段フィードバックキューとして実装された。既定の SCHED OTHER ポリシーは、オリジナル 4.4BSD スケジューリングか、Solaris のような伝統的 UNIX 風オペレーティングシステム方法である。選択されたスケジューラーに依存する。SCHED 4BSD か SCHED M2 カーネルオプションを使えば選択できるようになる。タイムシェアリングキューのおもな目標のうち 1 つは、I/Oバウンドスレッドへプライオリティブーストさせ( インタラクティブタスクのために良い応答時間をカーネルに許可する )、公平性を保証する。各 LWP は優先度とタイムカンタム( スケジューラーによって割り当てられた CPU 動作時間の合計 )を持っている。タイムシェアリングキューにおいて、両方の値はスケジューラーによって動的に計算される。
Threads running with the SCHED FIFO policy, which is a real-time policy, have a fixed priority. That is, the kernel does not change the priority dynamically. Only the super user can set the scheduling policy to SCHED FIFO. Under this policy, a thread runs until completion, or it:
SCHED FIFO ポリシーで走るスレッドは、リアルタイムポリシーであり、固定された優先度を持っている。つまり、カーネルは動的に優先度を変更できない。スーパーユーザーのみが SCHED FIFO にスケジューリングポリシーを設定できる。このポリシーのもとではスレッドは完了するか、以下のようになるまで動作する:
- Voluntarily gives up the CPU (yields).
- Blocks on I/O operation or other resources (memory allocation, locks, etc).
- Gets preempted by a higher priority real-time thread.
- 自発的に CPU を停止する( 委譲 )
- I/O 操作か、他のリソース( メモリ確保、ロックなど )でブロックする
- より高い優先度のリアルタイムスレッドによってプリエンプトを取得される
SCHED RR works in the same way as SCHED FIFO, except threads running with this policy have a time- quantum (time-slice), which by default is 100 ms. Thus, unless it encounters one of the three cases above, the thread finishes when its time-quantum expires. Threads at the same priority level are processed in a round-robin way.
SCHED RR は SCHED FIFO と同じように動作するが、このポリシーで動作するスレッドは既定で 100 ms のタイムカンタム( タイムスライス )で動作する。このように、上記 3 つのうち 1 つが起きるまでは、タイムカンタムの満了よってスレッドは終了する。同じ優先度のスレッドは、ラウンドロビンで処理される。
Figure 1: Real-time thread dispatch latency (threads bound to pset), 8 core Xeon with background load.
図1: リアルタイムスレッドがレイテンシをディスパッチする( pset するときのスレッドバウンド )。8 コア Xeon でのバックグラウンドロード。
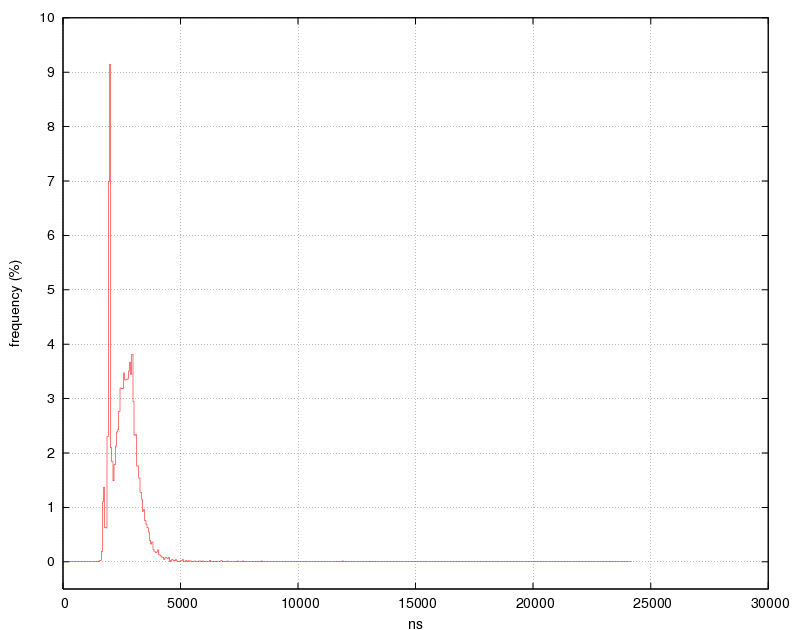
A simple latency test with two SCHED FIFO threads bound to the same CPU when the system is under load (running ./build.sh -j16) has shown that NetBSD with kernel preemption enabled tends to respond within 5 microseconds (see Figure 1). Microsecond-level latencies for real-time threads are usually what real-time operating systems, like QNX or VxWorks, guarantee. As we see, response times of real-time threads in NetBSD 5.0 are similar to other real-time operating systems.
システムが低負荷( ./build.sh -j16 を実行 )の場合、2 つの SCHED FIFO スレッドの簡単なレイテンシテストは同じ CPU のためにバウンドする。カーネルプリエンプションを有効にした NetBSD が 5 マイクロ秒以内に応答する傾向がある( 図 1 )。リアルタイムスレッドのためのマイクロ秒レベルのレイテンシは、通常 QNX や VxWorks 製品のようなリアルタイムオペレーティングシステムである。我々が見たように、NetBSD 5.0 でのリアルタイムスレッドの応答時間は、他のリアルタイムオペレーティングシステムと同様である。
The following C code fragment illustrates how to use the SCHED FIFO policy and set highest priority for the current (calling) thread:
以下の C コード断片は SCHED FIFO ポリシーの使い方と、現在のスレッド( 呼び出した側 )に最高優先度を設定する方法を示す。
struct sched_param sp;
memset(&sp, 0, sizeof(struct sched_param));
sp.sched_priority = sched_get_priority_max(SCHED_FIFO);
if (pthread_setschedparam(pthread_self(), SCHED_FIFO, &sp)) {
errx(EXIT_FAILURE, "pthread_setschedparam: %s", strerror(error));
}
See the sched(3) and pthread schedparam(3) manual pages for a full description of scheduling functions.
スケジューリング関数についての完全な説明は sched(3) と pthread schedparam(3) マニュアルページを参照。
Thread affinity スレッド親和性
Thread affinity is the ability to bind threads to run only on a specified processor (or processors). This functionality is relevant to SMP systems and provides an effective way to increase CPU utilization, avoid CPU cache thrashing, ensure concurrency, and guarantee fast response times. These are of particular benefit to real-time applications.
スレッド親和性は、特定のプロセッサ( 単数または複数 )のみにスレッドを動作させるように結びつける能力である。この機能は SMP システムのためのもので、CPU 利用を増加するための効果的な方法を提供する。CPU キャッシュスラッシングの回避、並行性の確保、そして速い応答時間を保証する。リアルタイムアプリケーションのために特に効果がある。
Internally, the scheduler (this part of functionality is also called the dispatcher) tries to balance between two opposite tasks - utilize all processors and maintain thread affinity. In NetBSD 5.0, this is achieved by means of per-CPU run-queues, thread migration and balancing mechanisms. However, balancing and migration decisions are heuristic and based on observations of thread behaviour made by the kernel, meaning that the decisions made might not be optimal in all given situations. For example, the scheduler is not aware of the workload a thread is going to process, or of the relationships between threads. Because developers have such knowledge of their applications, interfaces to control affinity are provided. There are two different interfaces in NetBSD to implement thread affinity: dynamic CPU sets and processor sets.
内部ではスケジューラー( この機能の一部は、ディスパッチャとも呼ばれる )は 2 つの正反対のタスクのバランスをとる - すべてのプロセッサを利用し、スレッド親和性を維持する。NetBSD 5.0 では、これは CPU ごとのランキュー、スレッドマイグレーションと分散機構によって達成された。しかし、分散とマイグレーションを決定することはヒューリスティックであり、カーネルがスレッドの挙動を監視することに基づいているので、この決定がすべての与えられた状況{ ???? }に最適ではない可能性を意味する。たとえば、スケジューラーはプロセスに入ったスレッドの仕事量を把握していないし、スレッド間の関係も把握していない。開発者は彼らのアプリケーションの知識として持っているので、親和性を管理するためのインターフェースが提供されている。NetBSD でのスレッド親和性についてのインターフェースには 2 つの差異がある。動的 CPU 割り当てとプロセッサ割り当てだ。
Dynamic CPU sets is an interface similar to the CPU sets found in Linux and recent FreeBSD systems. It allows binding (pinning) a thread to the processors expressed via affinity mask (a simple bit-mask). Here is a C code fragment which creates a dynamic CPU set, adds the first processor (cpu0) to the set, and sets the affinity mask to the current (calling) thread:
動的 CPU 割り当ては、Linux や最近の FreeBSD システムに見られる CPU 割り当てのようなインターフェースである。親和性マスク( 簡単なビットマスクだ )によるプロセッサへスレッドを結び付ける( 繋ぐ )。ここに C コード断片がある。これは動的 CPU 割り当てを生成し、最初のプロセッサ( cpu0 )を割り当てに追加し、現在のスレッド( 呼び出し側 )へ親和性マスクを割り当てる。
cpuset_t *cset;
pthread_t pth;
cpuid_t ci;
cset = cpuset_create();
if (cset == NULL) {
err(EXIT_FAILURE, "cpuset_create");
}
/* Set the first processor (cpu0). */
ci = 0;
cpuset_set(ci, cset);
/* Set affinity mask to the current thread. */
pth = pthread_self();
error = pthread_setaffinity_np(pth, cpuset_size(cset), cset);
if (error) {
errx(EXIT_FAILURE, pthread_setaffinity_np: %s", strerror(error));
}
/*
* At this point, the current thread runs on the first processor (cpu0).
* The set can be destroyed now (or re-used for other thread, for example),
* since it is already "applied" to the thread.
*/
cpuset_destroy(cset);
perform_work();
Wrappers to set and get the process affinity are also provided:
プロセッサ親和性を設定したり取得するためのラッパーも提供されている。
int sched_getaffinity_np(pid_t pid, size_t size, cpuset_t *cpuset); int sched_setaffinity_np(pid_t pid, size_t size, cpuset_t *cpuset);
Note that while the thread is bound to the first processor, any other process/thread could also run on this processor, and share the time. A full description of dynamic CPU sets API could be found in the affinity(3) and cpuset(3) manuals. Unfortunately, neither POSIX nor other standards define any interfaces to control thread affinity and interfaces provided by various operating systems differ, so these calls are not expected to be portable.
なお、スレッドが最初のプロセッサへ結びつけられている間、他のあらゆるプロセッサ/スレッドもこのプロセッサで動作できるし、時間も共有される。動的 CPU 割り当て API についての完全な説明は、affinity(3) と cpuset(3) マニュアルにある。残念ながら、POSIX や他の標準は、スレッド親和性を管理するインターフェースや様々なオペレーティングシステムの違いで提供されるインターフェースを定義してもいない。よって、これらの呼び出しはポータブルを期待できない。
Processor sets is an interface which allows assigning processors to threads. Assigned processors are forced to run only bound threads (or processes). Thus, processor sets are more of a resource pool based solution. A similar interface is found in the Solaris and HP-UX operating systems. Here is a C code fragment which forces a processor to run only the current (calling) process:
プロセッサセットとは、スレッドへプロセッサを割り当てるためのインターフェースである。割り当てられたプロセッサは、バウンドスレッド(またはバウンドプロセス)のみを実行することを強制する。このようにプロセッサセットはより一層 資源ベースの解決策となる。同様のインターフェースは Solaris や HP-UX オペレーティングシステムにも見られる。現在のプロセス(呼び出し側)のみを実行するようにプロセッサに強制する C コード断片を示す。
psetid_t psid;
cpuid_t ci;
if (pset_create(&psid) == -1) {
err(EXIT_FAILURE, "pset_create");
}
/*
* Assign cpu0 to the processor set.
*/
ci = 0;
if (pset_assign(psid, ci, NULL) == -1) {
err(EXIT_FAILURE, "pset_assign");
}
/*
* Bind the current process to the processor-set.
*/
if (pset_bind(psid, P_PID, P_MYID, NULL) == -1) {
err(EXIT_FAILURE, "pset_bind");
}
/*
* At this point, the first processor (cpu0) runs _only_ the current process.
*/
perform_work();
/*
* Destroy the processor set.
* This operation releases all assigned processors and bound threads.
*/
if (pset_destroy(psid) == -1) {
err(EXIT_FAILURE, "pset_destroy");
}
Note that unlike the previous example with dynamic CPU sets, in this example the first processor (cpu0) would run only one bound process, and no other processes. A full description of the processor sets API can be found in the pset(3) manual page. This interface is not defined by any standards either. However, the API is expected to be nearly compatible with Solaris and HP-UX.
先ほどの動的 CPU セットの例とは異なる。この例では最初のプロセッサ(cpu0) はたった 1 つのバウンドプロセスのみを実行し、他のプロセスは実行しない。プロセッサセット API の完全な説明は pset(3) マニュアルページにある。このインターフェースはどの標準にも定義されていない。しかし API は Solaris や HP-UX とほぼ互換性があることが期待される。
To find out how many processors are configured in the system, there is a standard option to sysconf(3):
システムにいくつのプロセッサが設定されているかを見つける方法は、sysconf(3) の標準オプションにある。
ncpu = sysconf(_SC_NPROCESSORS_CONF);
The flexibility to choose between two interfaces with different approaches, found in various UNIX-like oper- ating systems, allows developers to use the interface which best suits the needs of their applications.
異なるアプローチにより 2 つのインターフェースを選べるための柔軟性は、様々な UNIX 風オペレーティングシステムに見られるし、開発者が彼らのアプリケーションが必要とする最良の一式のインターフェースを使うことを許可する。
Controlling the scheduling of processes and threads プロセスとスレッドのスケジューリング管理
NetBSD also provides two utilities to control scheduling and thread affinity. These utilities can be used by administrators and developers. The schedctl(8) command allows changing scheduling priority and class, and setting thread/process affinity. The following examples illustrate some possible uses of this utility.
NetBSD はスケジューリング管理とスレッド親和性のために 2 つのユーティリティも提供する。これらのユーティリティは管理者と開発者が使える。schedctl(8) コマンドはスケジューリングの優先度とクラスを変更し、スレッド/プロセス親和性を設定できる。このユーティリティで出来ることいくつかの例を示す。
Show scheduling information about PID "123":
PID 123 のスケジューリング情報を表示する:
# schedctl -p 123 LID: 1 Priority: 43 Class: SCHED_OTHER Affinity (CPUs): <none>
Set the affinity to CPU 0 and CPU 1, policy to SCHED RR, and priority to 63 for thread whose ID is "1" in process whose ID is "123":
CPU 0 と CPU 1 に親和性を設定し、ポリシーを SCHED RR にし、プロセス ID 123 のスレッド ID 1 の優先度を 63 にする。
# schedctl -p 123 -t 1 -A 0,1 -C SCHED_RR -P 63
Run the top(1) command with real-time priority:
top(1) コマンドをリアルタイム優先度で走らせる:
# schedctl -C SCHED_FIFO top
Traditional utilities like top(1) (with the -t option to enable thread-view) and ps(1) (with the -l option) can be used to monitor the general thread activity.
top(1) ( -t オプションでスレッドビューを有効 )や ps(1) ( -l オプションも使う )のような伝統的ユーティリティは通常のスレッド活動を監視するために使える。
To control processor sets, psrset(8) is provided, which is nearly compatible with the one found in Solaris. The following example illustrates how to create a processor set, assign CPU 9 to it, and run httpd on that processor set.
プロセッサー割り当てを制御するために psrset(8) が提供されている。これは Solaris にあるものと割りと互換性がある。以下の例では、プロセッサセットを生成し、CPU 9 に割り当て、プロセッサセットで httpd を走らせる方法を示す。
Print current processor sets:
現在のプロセッサセットを印字する:
# psrset system processor set 0: processor(s) 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Create a new processor set, which is assigned an ID of 1, and add CPU 9 to processor set 1:
新しいプロセッサセットを生成する。これは ID 1 に割り当てられ、CPU 9 をプロセッサセット 1 へ追加する:
# psrset -c 1 # psrset -a 1 9
Print current processor sets. Note that there is now a user-created processor set with an ID of 1, and that CPU 9 is now in processor set 1 and no longer in 0:
現在のプロセッサセットを印字する。なお、現在 利用者が生成した ID 1 のプロセッサセットがあり、CPU 9 はプロセッサセット 1 になっており、0 ではなくなっている。
# psrset system processor set 0: processor(s) 0 1 2 3 4 5 6 7 8 10 11 12 13 14 15 user processor set 1: processor(s) 9
Execute httpd within processor set 1:
プロセッサセット 1 上で httpd を実行する:
# psrset -e 1 /etc/rc.d/httpd start
Note that top(1) shows httpd running on CPU 9:
top(1) で CPU 9 上で httpd が走っていることを表示する:
# top | grep httpd 29469 www 85 0 164K 1468K select/9 0:04 0.68% 0.68% httpd 15229 www 85 0 164K 1404K select/9 3:15 0.00% 0.00% httpd 18574 www 85 0 164K 1688K select/9 2:16 0.00% 0.00% httpd 14208 www 85 0 164K 1336K select/9 2:15 0.00% 0.00% httpd
A small cpuctl(8) utility is also available, which can change the state of CPU to online/offline, as well as identify its model and features. Example output from a machine with "AMD Shanghai" (codename) processors:
小柄なユーティリティ cpuctl(8) も有効である。これは CPU の状態を オンライン/オフラインに変更し、モデルと機能を区別する。コードネーム "AMD Shanghai" プロセッサのマシンでの出力例:
# cpuctl list Num HwId Unbound LWPs Interrupts Last change ---- ---- ------------ -------------- ---------------------------- 0 0 online intr Sat Nov 8 16:33:40 2008 1 1 online intr Sat Nov 8 16:33:40 2008 2 2 online intr Sat Nov 8 16:33:40 2008 3 3 online intr Sat Nov 8 16:33:40 2008 4 4 online intr Sat Nov 8 16:33:40 2008 5 5 online intr Sat Nov 8 16:33:40 2008 6 6 online intr Sat Nov 8 16:33:40 2008 7 7 online intr Sat Nov 8 16:33:40 2008 8 8 online intr Sat Nov 8 16:33:40 2008 9 9 online intr Sat Nov 8 16:33:40 2008 10 a online intr Sat Nov 8 16:33:40 2008 11 b online intr Sat Nov 8 16:33:40 2008 12 c online intr Sat Nov 8 16:33:40 2008 13 d online intr Sat Nov 8 16:33:40 2008 14 e online intr Sat Nov 8 16:33:40 2008 15 f online intr Sat Nov 8 16:33:40 2008
# cpuctl identify 0 cpu0: AMD Unknown AMD64 CPU (686-class), 2999.67 MHz, id 0x100f40 cpu0: features 178bfbff<FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR> cpu0: features 178bfbff<PGE,MCA,CMOV,PAT,PSE36,CFLUSH,MMX> cpu0: features 178bfbff<FXSR,SSE,SSE2,HTT> cpu0: features2 802009<SSE3,MONITOR,CX16,POPCNT> cpu0: features3 efd3fbff<SCALL/RET,NOX,MXX,FFXSR,P1GB,RDTSCP,LONG,3DNOW2,3DNOW> cpu0: features4 37ff<AHF,CMPLEGACY,SVM,EAPIC,ALTMOVCR0,LZCNT,SSE4A,MISALIGNSSE,3DNOWPREFETCH,OSVW,IBS,SKINIT,WDT> cpu0: "AMD Engineering Sample" cpu0: I-cache 64KB 64B/line 2-way, D-cache 64KB 64B/line 2-way cpu0: L2 cache 1MB 64B/line 16-way cpu0: ITLB 32 4KB entries fully associative, 16 4MB entries fully associative cpu0: DTLB 48 4KB entries fully associative, 48 4MB entries fully associative cpu0: L3 cache 2MB 64B/line direct-mapped cpu0: Initial APIC ID 0 cpu0: AMD Power Management features: 0x1f9<TS,TTP,HTC,STC,100,HWP,TSC> cpu0: family 0f model 04 extfamily 01 extmodel 00
This utility can also be useful to developers who are writing multithreaded applications and want to test them under a variety of CPU conditions.
このユーティリティは、マルチスレッドアプリケーションを書いて、様々な CPU 状況でテストしたい開発者にも使いやすい。
Conclusion 終わりに
NetBSD is a general-purpose operating system, with a scalable 1:1 threading implementation and flexible interfaces to control scheduling and threads. This scalable implementation allows it to provide high quality POSIX real-time extensions and reliably suit the needs of embedded systems. NetBSD also provides modern solutions to ensure good performance for threaded workloads, which are increasingly prevalent in today's world of multi-core and multi-processor systems.
NetBSD は通常目的のオペレーティングシステムである。スケーラブル 1:1 スレッディング実装し、スケジューリングとスレッドを制御するための柔軟なインターフェースがある。このスケーラブル実装によって 高品質な POSIX リアルタイム拡張を提供し、組み込みシステムの要求に確実にぴったりである。NetBSD は threaded workloads のための確実で良いパフォーマンスのためにモダンなソリューションも提供する。これは今日のマルチコアやマルチプロセッサシステムでますます一般化している。