2013-06-01 :-)
_ 読書メーター
2013年5月の読書メーター
読んだ本の数:7冊
読んだページ数:1962ページ
ナイス数:13ナイス
 ゲームクリエイターが知るべき97のこと
読了日:5月24日 著者:
ゲームクリエイターが知るべき97のこと
読了日:5月24日 著者: アラン・ケイ (Ascii books)
読了日:5月15日 著者:アラン・C. ケイ
アラン・ケイ (Ascii books)
読了日:5月15日 著者:アラン・C. ケイ 考具 ―考えるための道具、持っていますか?の感想
アイデアを出すための手段いろいろ。あえて制限をつけることでアイデアをひねり出す
読了日:5月12日 著者:加藤 昌治
考具 ―考えるための道具、持っていますか?の感想
アイデアを出すための手段いろいろ。あえて制限をつけることでアイデアをひねり出す
読了日:5月12日 著者:加藤 昌治 魔法少女育成計画 restart (後) (このライトノベルがすごい! 文庫)の感想
決着。著者の好みは年増云々、と言ったのは取り消します。ラズリーヌはお気に入りだったのにいーーー
読了日:5月5日 著者:遠藤 浅蜊
魔法少女育成計画 restart (後) (このライトノベルがすごい! 文庫)の感想
決着。著者の好みは年増云々、と言ったのは取り消します。ラズリーヌはお気に入りだったのにいーーー
読了日:5月5日 著者:遠藤 浅蜊 魔法少女育成計画 restart (前) (このライトノベルがすごい! 文庫)の感想
デスゲームと推理。途中で魔法少女と魔法効果を整理してたけど、あれは読者への挑戦であろうとは思うんだけど、犯人がさっぱり分からぬ / マジカルデイジーはさすがに生き残ると思ってたんだけど、前の巻といい、もしかしてこの著者は年増が嫌いなんだろうか
読了日:5月4日 著者:遠藤 浅蜊
魔法少女育成計画 restart (前) (このライトノベルがすごい! 文庫)の感想
デスゲームと推理。途中で魔法少女と魔法効果を整理してたけど、あれは読者への挑戦であろうとは思うんだけど、犯人がさっぱり分からぬ / マジカルデイジーはさすがに生き残ると思ってたんだけど、前の巻といい、もしかしてこの著者は年増が嫌いなんだろうか
読了日:5月4日 著者:遠藤 浅蜊 魔法少女育成計画 (このライトノベルがすごい! 文庫)の感想
まどか☆マギカを知る前に読みたかった。ファヴが合理的に使命をもって行動しているんであればよかったんだけど快楽のために行動してるのが残念
読了日:5月4日 著者:遠藤 浅蜊
魔法少女育成計画 (このライトノベルがすごい! 文庫)の感想
まどか☆マギカを知る前に読みたかった。ファヴが合理的に使命をもって行動しているんであればよかったんだけど快楽のために行動してるのが残念
読了日:5月4日 著者:遠藤 浅蜊 はじめてのOSコードリーディング ~UNIX V6で学ぶカーネルのしくみ (Software Design plus)の感想
UNIX V6のコードを読みながらオペレーティングシステムの仕組みを読み解く。当然ながらコードがたくさん出てくるが、それにより説明が具体化されるので、抽象化された文章よりもむしろ理解しやすい。これはもはやオペレーティングシステムの教科書と言ってよかろう。プロセス、割り込み、ファイルシステム、起動など幅広いが、スケジューラのところが熱い。スワッパの説明など感動すら覚える
読了日:5月3日 著者:青柳 隆宏
はじめてのOSコードリーディング ~UNIX V6で学ぶカーネルのしくみ (Software Design plus)の感想
UNIX V6のコードを読みながらオペレーティングシステムの仕組みを読み解く。当然ながらコードがたくさん出てくるが、それにより説明が具体化されるので、抽象化された文章よりもむしろ理解しやすい。これはもはやオペレーティングシステムの教科書と言ってよかろう。プロセス、割り込み、ファイルシステム、起動など幅広いが、スケジューラのところが熱い。スワッパの説明など感動すら覚える
読了日:5月3日 著者:青柳 隆宏
読書メーター



_ [ruby][Yahoo][係り受け解析][自然言語処理][NLP]Yahoo デベロッパーネットワークの日本語係り受け解析APIを使ってみる
テキスト解析:日本語係り受け解析API - Yahoo!デベロッパーネットワーク
こんな
# coding: utf-8
# Yahoo デベロッパーネットワーク の 日本語係り受け解析API を使う
# http://developer.yahoo.co.jp/webapi/jlp/da/v1/parse.html
#
# ref.
# [を] ヤフーの日本語係り受け解析APIとサンプルプログラム「なんちゃって文章要約」
# http://chalow.net/2008-08-21-1.html
#
require 'uri'
require 'open-uri'
require 'rexml/document'
require 'pp'
def syntactic_parse(xml)
syntactic ||= []
doc = REXML::Document.new(xml)
doc.elements.each('ResultSet/Result/ChunkList/Chunk') do |chunk|
chunks = ""
chunk.elements.each('MorphemList') do |ml|
ml.elements.each("Morphem/Surface") do |mo|
chunks << mo.text
end
end
syntactic << chunks
end
return syntactic
end
def syntactic_analysis(text)
apiuri = "http://jlp.yahooapis.jp/DAService/V1/parse"
appid = "?appid=" + ここにあなたのAPI IDを入れる
sentence = "&sentence=" + URI.encode(text)
uri = apiuri + appid + sentence
response = open(uri).read()
syntactic = syntactic_parse(response)
return syntactic
end
def main(argv)
text = argv[0]
syntactic = syntactic_analysis(text)
puts syntactic
end
main(ARGV)
% ruby parse1.rb 隣の客はよく柿食う客だ 隣の 客は よく 柿食う 客だ
_ [ruby][Yahoo][係り受け解析][自然言語処理][NLP][マルコフ連鎖]Yahoo デベロッパーネットワークの日本語係り受け解析APIを使ってマルコフ連鎖してみる
あと、単純にYahooの形態素解析APIを使わないのは、言葉と言葉のつながりが学習できないと判断したからです。
例えば、「うちの庭には二羽鶏がいます。」をYahooの形態素解析APIと日本語係り受け解析APIでやってみると、
→形態素解析:うち/の/庭/に/は/二羽/鶏/が/い/ます/。
→日本語係り受け解析:うちの/庭には/二羽鶏が/います。
となるんですが、日本語係り受け解析ではランダムに並び替えられても意味は分かりそうですよね。対して形態素解析では、ランダムになると正しく意味を把握するのがかなり難しくなります。
今回の入力の形式上、言葉の順番という概念は存在しないので、ランダムに並べた時に意味が分かるというのは非常に重要な要素だと考えたわけです。
ということで形態素解析するよりも係り受け解析のほうがマルコフ連鎖作成時に単語の繋がりをあまり意識しなくていいので楽ちん。
マルコフ連鎖の考え方はこちらと同じ → マルコフ連鎖してみた - hitode909の日記
# coding: utf-8
require 'uri'
require 'open-uri'
require 'rexml/document'
require 'pp'
# XML を解析して係り受けごとにまとめる
def syntactic_parse(xml)
syntactic ||= []
doc = REXML::Document.new(xml)
doc.elements.each('ResultSet/Result/ChunkList/Chunk') do |chunk|
chunks = ""
chunk.elements.each('MorphemList') do |ml|
ml.elements.each("Morphem/Surface") do |mo|
chunks << mo.text
end
end
syntactic << chunks
end
return syntactic
end
# 係り受け解析
def syntactic_analysis(text)
apiuri = "http://jlp.yahooapis.jp/DAService/V1/parse"
appid = "?appid=" + ここにあなたのAPI IDを入れる
sentence = "&sentence=" + URI.encode(text)
uri = apiuri + appid + sentence
response = open(uri).read()
syntactic = syntactic_parse(response)
return syntactic
end
# マルコフ連鎖 学習
def learn(syntacticed)
statetab ||= {}
size = syntacticed.size
0.upto(size - 2) {|index|
w1 = syntacticed[index]
w2 = syntacticed[index + 1]
statetab[w1] ||= []
statetab[w1] << w2
}
return statetab
end
N_MAX = 5
# マルコフ連鎖 生成
def generate(input, statetab)
output = ""
term = statetab.keys.sample
output << term
0.upto(N_MAX) {|n|
if statetab.key?(term)
term = statetab[term].sample
else
term = statetab.keys.sample
end
output << term
}
return output
end
# テキスト読むだけ
# テキストの途中に \n があると chomp だと削除できないようなので gsub しとく
def read(text)
File.open(text).read.gsub("\n", "")
end
def main(argv)
file = argv[0]
input = read(file)
syntactic = syntactic_analysis(input)
statetab = learn(syntactic)
output = generate(input, statetab)
puts output
end
main(ARGV)
こんなテキストファイルを用意する。Yahoo の係り受け解析APIに渡せるのは 4KB までなので注意。
ほむらちゃん、ごめんね。私、魔法少女になる。 私、やっとわかったの。叶えたい願いごと見つけたの。だからそのために、この命を使うね。 ごめん。ホントにごめん。これまでずっと、ずっとずっと、ほむらちゃんに守られて、望まれてきたから、今の私があるんだと思う。 絶対に、今日までのほむらちゃんを無駄にしたりしないから。 全ての魔女を、生まれる前に消し去りたい。全ての宇宙、過去と未来の全ての魔女を、この手で。 今日まで魔女と戦ってきたみんなを、希望を信じた魔法少女を、私は泣かせたくない。最後まで笑顔でいてほしい。 それを邪魔するルールなんて、壊してみせる、変えてみせる。 これが私の祈り、私の願い。 さあ!叶えてよ、インキュベーター!!
実行する。
% ruby markov1.rb text0.txt ほむらちゃん、ごめんね。私、やっとわかったの。叶えたい願いごと見つけたの。だから
ううむ
たんにカタコトな文章になっている。なので
2013-06-02 :-)
_ 午後
_ [NHK技研公開]NHK技研公開2013 ~期待、見たい、感じたい~
今年も行ってきた。
いつもどおりに用賀駅のバス停からバスに乗る。

入ります

入ってすぐにツアーの予約をしておく。

今年も食堂でおひる。食堂は 7 割くらい席が埋まっているんだけど、食堂が利用できることを皆どこで知るのか。私は RSS リーダーに登録している日記の人がNHK技研公開で食堂を利用しているのを見かけたから偶然にも知ることが出来たけど、食堂には親子連れや老人の団体などもたくさん居るくらいだから食堂利用はポピュラーな行動なのかもしれんけど、NHK技研公開のページには「食堂利用できます」などとはとくに書いておらず(食堂への経路は書いてある) それほど存在をアピールしてるわけでもないのに、これだけ利用者が居るのが謎である。もしかして NHK で放送してた。

NHK、指で物を触れた感覚を再現できる装置を開発 - ITmedia ニュース を見てくるなど。人数制限もしていて行列ができており説明は流れ作業のようだったので流されないうちに質問してきた。俺「説明のパネルには 4 点あれば充分のように書いてあるのに何故 5 点なのか」説明員「3 点で平面が表現できる。4 点で立体が表現できる。4 点あれば充分なのだが 1 点外す場合を考えて 5 点にした」という。

展示項目33 放送局で活躍する技術 のランドマーク表示システム「スカイマップ」。テレビ東京の 空から日本を見てみよう みたいな。説明員「撮影時のカメラの角度や望遠倍率などから距離を計算し地図上に表示する仕組みである。あくまで取材の支援が目的であり、ざっくりとした位置関係が分かればいいので、ランドマークの正確な位置は表示していない。まともにやろうとするとカメラのブレやヘリコプターのブレも考慮せねばならず大変である。ランドマークの位置は正確ではないのでテレビ放送には使わない。クレームが来るかもしれないから :-) 」とのことだった。

展示項目14 評判分析のためのTwitter解析技術 説明員「Twitter の post と番組内容を照らしあわせて、この番組のことを言っているのだろう、という程度に抽出する。post からポジティブ、ネガティブなどを判定(あらかじめ辞書を用意しておく) して番組の評判の参考にする。ただ、post の内容が、( たとえば TPP 交渉に関する番組の場合 )番組そのものへの意見なのか、政府への意見なのかは判別できないので、それは今後の課題である」だそうだ。

ガイドツアーでまわっている途中、我々が説明を受けているブースの隣のブースで、客が「いまどきは Youtube などの劣化画質でコンテンツを楽しむのに、なぜ高品質を求めるのか、NHK は間違っている云々」と説明員に噛み付いているひとがいた。説明員も大変だなあ。
_ TEAMΩANS GT5部のサイト開設のお知らせ
このチームではプレイヤー個人が自分なりのプレイスタイルでまったり遊ぶことを主眼に置いたまったりチームとなっております。
初心者からエキスパートまで、オープン部屋でプレイするプレイヤーもいればラウンジでゆっくりドリフトorグリップ共に幅広いメンバーが集まっております。
モラルを守り、かつまた会ってみたいと思ってもらえるような楽しく、面白いチームになれるよう心がけております。
他にもルールなどがあるので、リンク先のページをご確認ください。
2013-06-03 :-(
_ 午後
1300 ガジェット
_ リッジレーサー7 ARC 2013 開催中止のお知らせ
開催を予定してたりしなかったりする ARC 2013 ですが、主催者の私の仕事が今後 3, 4 ヶ月は過密になり( 他のプロジェクトメンバーは土日出勤していた ) よって、開催は見送ります。
2013-06-04 :-(
_ 午後
1300 ガジェット
_ 仕事場が冷房ききすぎて寒い
むい
_ ドライアイ
自社にきた初日(昨日だ)は空調による影響か、目が乾いてしまい猛烈に辛かったんだが、今日はとくに目の乾きを感じなかった。慣れたか
2013-06-05 :-(
_ 午後
1300 ガジェット
_ 夜
1830 飯







2013-06-06 :-(
2013-06-07 :-(
_ 午後
1300 ガジェット
_ トマトが赤くなった

_ 表彰式・新入社員歓迎会
@ホテルニューオータニ
数年ぶりの自社のイベントに参加した。というか去年あたりも開催してた気がするがたしか体調不良により欠席したような。
ビュッフェに行列が出来ていたので捌けるのを待っていたら何も食べないうちにビュッフェが終了したので、腹いせに同僚が持っていた食事を撮影しておいた。


この反省を活かし、おやつタイムが始まる前におやつテーブルに待機しておいたのでおやつ充を満喫できた。


_ ,
画像処理がおもな業務の会社に勤務しておきながら、ビットマップファイルの構造もロクに理解していないオジサンがこちら。
2013-06-08 :-)
_ 午前
1030 起床 && 部屋掃除
_ [Kalafina]Kalafina LIVE TOUR 2013 "Consolation"
@中野サンプラザ
友人からチケットを頂いたので行ってきた。
最後に中野サンプラザに来たのは 2001/10/14 masami okui concert tour 2001 -DEVOTION- 奥井雅美 らしいです。ぉぉぅ。中野駅じたいは LINEAR のときなどにたまに来ていたんだが、それでも中野駅前の変貌ぶりに驚いた。いやまあ駅前ロータリーが潰れて階段が出来てただけですが。
友人から頂いた座席は 2 階席だったものの、1 階は立ったり座ったりの展開だったし、むしろ 2 階は私の席の眼前がどうも関係者席(年齢的に親族席か?)のようだし周囲のひとたちも座ったままで落ち着いておりとてもよい席でありました。Kalafina の歌はポップな感じではなく、クラシックのように座って聞く以外に反応しようがないのでひたすら座っていたんだが、1 階のひとたちはアレはどういうリズムに反応したんだろうかと (意訳: 立つのが億劫)
劇場版まどか☆マギカ を見て泣くようなオジサン[ 20121029#p05 ]が「ひかりふる」を聞いて泣いてしまってもそれは何ら不思議なことではない。
2013-06-09 :-)







_ [はてな][スクレイピング][ruby][mechanize]はてなブログをスクレイピングする
# coding: utf-8
# hatenablog をスクレイピング
#
# 使い方:
# hatenablog.rb <hatenablog URI> [カテゴリ]
#
# 例:
# ruby hatenablog.rb http://jkondo.hatenablog.com/ > jkondo.txt
#
# ruby hatenablog.rb http://dennou-kurage.hatenablog.com/ 仕事観 > kurage.txt
#
require 'mechanize'
require 'uri'
require 'pp'
def get_text(uri)
agent = Mechanize.new
agent.get(uri)
texts = ""
while true
agent.page.at("//div[@class='entry-content']").children.each {|node|
text = node.text
texts << text
}
link = agent.page.link_with(:text => '次のページ')
break if link == nil
agent.page.link_with(:text => '次のページ').click
end
return texts
end
def main(argv)
uri_base = argv[0]
cat = ""
if argv[1] != nil
cat = "category/" + URI::encode(argv[1])
end
uri = uri_base + cat
text = get_text(uri)
puts text
end
main(ARGV)
_ [自然言語処理][係り受け解析][構文解析][ruby][NLP]テキストを係り受け解析する
前提
テキスト解析サンプルコード:係り受け解析 - Yahoo!デベロッパーネットワーク
日本語係り受け解析API の制限が以下のようになっている。
日本語係り受け解析Web APIは、24時間以内で1つのアプリケーションIDにつき50000件のリクエストが上限となっています。また、1リクエストの最大サイズを4KBに制限しています。詳しくは「利用制限」をご参照ください。
UTF-8 エンコード 1 文字は最大 4 バイトでエンコードされるとする。
それを URI.encode すると最大 12 バイトになると見積もる
( たとえば 4 バイト 0xAA 0xBB 0xCC 0xDD であるとすると、これが URI.encode されるとテキストで表現されるので %AA %BB %CC %DD の 12 文字、つまり 12 バイトになる )
↓リクエストパラメータのうち &sentence= までで 152 バイトある。
http://jlp.yahooapis.jp/DAService/V1/parse?appid=<あなたのアプリケーションID>&sentence=
↓リクエストに指定できる sentence としては 3848 バイト。
(4 * 1000) - 152 = 3848
上述のように 1 文字 12 バイトとして 320 文字まで指定できる。
3848 / 12 = 320
320 文字はギリギリなので、これをプログラムで扱うときは。まあざっくり 300 文字までとしてみる。
与えられたテキストが長文だった場合を考慮して、最初に「。」でぶったぎっておいて、300 文字を超えないように文を再度連結していく。しかしそもそも「。」までが 300 文字を超えるような文もあるわけだが、それは無視する(どこで区切るのか割りと重要かもそれんけどよく分からないのでスルー)。
実装
とりあえず作ったのがこちら。
syntactic.rb としておく。
# coding: utf-8
# Yahoo デベロッパーネットワーク の 日本語係り受け解析API を使う
# http://developer.yahoo.co.jp/webapi/jlp/da/v1/parse.html
require 'uri'
require 'open-uri'
require 'rexml/document'
require 'pp'
module NLP
module Syntactic
SENTENCE_LENGTH_MAX = 300
def parse(xml)
syntactic ||= []
doc = REXML::Document.new(xml)
doc.elements.each('ResultSet/Result/ChunkList/Chunk') do |chunk|
chunks = ""
chunk.elements.each('MorphemList') do |ml|
ml.elements.each("Morphem/Surface") do |mo|
chunks << mo.text
end
end
syntactic << chunks
end
return syntactic
end
def build_sweep(text)
text.gsub!("\n", "")
text.rstrip!
text.lstrip!
text.gsub!(/\A +/, "")
text.gsub!(/ /, "")
text.chomp!
text.gsub!(/[\r\n]/, "")
return text
end
def build_sentence(text)
text = build_sweep(text)
request_sentence ||= []
if text.length < SENTENCE_LENGTH_MAX
request_sentence << text
else
lump = ""
text.split(/。/).each {|sentence|
s = sentence + "。"
if (lump + s).length < SENTENCE_LENGTH_MAX
lump << s
else
request_sentence << lump
lump = ""
lump << s
end
}
end
return request_sentence
end
# 文章が長いのは無視
def _analysis(text)
apiuri = "http://jlp.yahooapis.jp/DAService/V1/parse"
appid = "?appid=" + ここにあたなのAPI IDを入れる
sentence = "&sentence=" + URI.encode(text)
request_uri = apiuri + appid + sentence
syntactics = ""
begin
response = open(request_uri).read()
syntactics = parse(response)
rescue => e
end
return syntactics
end
def analysis(text)
syntactics ||= []
sentences = build_sentence(text)
sentences.each {|s|
syntactics << _analysis(s)
}
return syntactics
end
end
end
使うときはこう。
# coding: utf-8
#
# 与えられたファイルを係り受け解析する
#
require 'pp'
require './syntactic'
include NLP::Syntactic
def build(text)
return NLP::Syntactic::analysis(text)
end
def read(text)
File.open(text).read
end
def main(argv)
infile = argv[0]
text = read(infile)
syntactic = build(text)
puts syntactic.join("\n")
end
main(ARGV)
_ [ベイズ][自然言語処理][ナイーブベイズ][ruby][NLP]文章をナイーブベイズする
以前作業しておいたナイーブベイズ[ 20130505#p04 ] を利用する。
# -*- encoding: utf-8 -*-
#
# ナイーブベイズを用いたテキスト分類 - 人工知能に関する断創録
# http://aidiary.hatenablog.com/entry/20100613/1276389337
#
def maxint()
return 2 ** ((1.size) * 8 -1 ) -1
end
def sum(data)
return data.inject(0) {|s, i| s + i}
end
include Math
require 'pp'
require 'json'
require 'yaml'
module NLP
# Multinomial Naive Bayes
class NaiveBayes
def initialize()
# カテゴリの集合
@categories = []
# ボキャブラリの集合
@vocabularies = []
# wordcount[cat][word] カテゴリでの単語の出現回数
@wordcount = {}
# catcount[cat] カテゴリの出現回数
@catcount = {}
# denominator[cat] P(word|cat)の分母の値
@denominator = {}
end
# ナイーブベイズ分類器の訓練
def train(data)
data.each {|d|
cat = d[0]
@categories << cat
}
@categories.each {|cat|
@wordcount[cat] ||= {}
@wordcount[cat].default = 0
@catcount[cat] ||= 0
}
# 文書集合からカテゴリと単語をカウント
data.each {|d|
cat, doc = d[0], d[1, d.length-1]
@catcount[cat] += 1
doc.each {|word|
@vocabularies << word
@wordcount[cat][word] += 1
}
}
@vocabularies.uniq!
# 単語の条件付き確率の分母の値をあらかじめ一括計算しておく(高速化のため)
@categories.each {|cat|
s = sum(@wordcount[cat].values)
@denominator[cat] = s + @vocabularies.length
}
end
# 事後確率の対数 log(P(cat|doc)) がもっとも大きなカテゴリを返す
def classify(doc)
best = nil
max = -maxint()
@catcount.each_key {|cat|
_p = score(doc, cat)
if _p > max
max = _p
best = cat
end
}
return best
end
# 単語の条件付き確率 P(word|cat) を求める
def wordProb(word, cat)
return (@wordcount[cat][word] + 1).to_f / (@denominator[cat]).to_f
end
# 文書が与えられたときのカテゴリの事後確率の対数 log(P(cat|doc)) を求める
def score(doc, cat)
# 総文書数
total = sum(@catcount.values)
# log P(cat)
sc = Math.log((@catcount[cat]) / total.to_f)
doc.each {|word|
# log P(word|cat
sc += Math.log(wordProb(word, cat))
}
return sc
end
# 総文書数
# def to_s()
# total = sum(@catcount.values)
# return "documents: #{total}, vocabularies: #{@vocabularies.length}, categories: #{@categories.length}"
# end
end
end # end of module
if __FILE__ == $0
# Introduction to Information Retrieval 13.2の例題
data = [
["yes", "Chinese", "Beijing", "Chinese"],
["yes", "Chinese", "Chinese", "Shanghai"],
["yes", "Chinese", "Macao"],
["no", "Tokyo", "Japan", "Chinese"]
]
# ナイーブベイズ分類器を訓練
nb = NLP::NaiveBayes.new
nb.train(data)
p nb
puts "P(Chinese|yes) = #{nb.wordProb('Chinese', 'yes')}"
puts "P(Tokyo|yes) = #{nb.wordProb('Tokyo', 'yes')}"
puts "P(Japan|yes) = #{nb.wordProb('Japan', 'yes')}"
puts "P(Chinese|no) = #{nb.wordProb('Chinese', 'no')}"
puts "P(Tokyo|no) = #{nb.wordProb('Tokyo', 'no')}"
puts "P(Japan|no) = #{nb.wordProb('Japan', 'no')}"
# テストデータのカテゴリを予測
test = ['Chinese', 'Chinese', 'Chinese', 'Tokyo', 'Japan']
puts "log P(yes|test) = #{nb.score(test, 'yes')}"
puts "log P(no|test) = #{nb.score(test, 'no')}"
puts nb.classify(test)
end
_ [構文解析][係り受け解析][社畜][ベイズ][自然言語処理][ナイーブベイズ][ruby][NLP]文章が社畜的かどうかをナイーブベイズ推定する
準備
社畜的文章の学習データとして 脱社畜ブログ のカテゴリ 仕事観 を利用する。
非社畜的文章の学習データとして jkondoのはてなブログ を利用する。
先ほどのコード[ 20130609#p04 ]でスクレイピングする。
% ruby hatenablog.rb http://jkondo.hatenablog.com/ > jkondo.txt
% ruby hatenablog.rb http://dennou-kurage.hatenablog.com/ 仕事観 > kurage.txt
先ほどのコード[ 20130609#p05 ]で係り受け解析しておく
% ruby parse.rb kurage.txt > kurage.2.txt
% ruby parse.rb jkondo.txt > jkondo.2.txt
判定の実装
先ほどのナイーブベイズのコード [ 20130609#p06 ] を利用する。
企業戦士として名高い クラウド・ストライフさん のセリフを社畜判定してみる。( FFシリーズ セリフ人気投票 )
# coding: utf-8
require './naivebayes'
require './syntactic'
include NLP::Syntactic
def get_words(text)
words = NLP::Syntactic::analysis(text)
words.flatten!
words.map! {|w|
w.gsub(/[、。\n]/, "")
}
return words
end
def build_learning(filepath, cat)
lines = File.open(filepath).readlines()
lines.map! {|w|
w.gsub(/[、。\n]/, "")
}
data = [cat, *lines]
return data
end
def classify(nb, text)
words = get_words(text)
cat = nb.classify(words)
# puts nb.score(words, "社畜")
# puts nb.score(words, "人間")
return "#{text} => #{cat}"
end
def main(argv)
shatiku_file = argv[0]
not_shatiku_file = argv[1]
shatiku_data = build_learning(shatiku_file, "社畜")
not_shatiku_data = build_learning(not_shatiku_file, "人間")
nb = NLP::NaiveBayes.new
nb.train([shatiku_data])
nb.train([not_shatiku_data])
text = %w(
興味ないね
エアリスはもう喋らない・・・笑わない・・・泣かない、怒らない・・・!
大切じゃない物なんか無い!
俺は俺の現実を生きる
俺は、お前の生きた証だ
指先がチリチリする。口の中はカラカラだ。目の奥が熱いんだ!
オレが・・・お前の生きた証・・・
引きずりすぎて少しすり減ったかな・・・
お前の分まで生きよう。そう決めたんだけどな…
もう・・・揺るがないさ・・
帰るぞ
俺は幻想の世界の住人だった。でも、もう幻想はいらない……俺は俺の現実を生きる
ここに女装に必要な何かがある。おれにはわかるんだ。いくぜ!
星よ・・・降り注げ!!
罪って…許されるのかな?
まだ終わりじゃない…終わりじゃないんだ!
俺はクラウド、ソルジャークラス1st
)
text.each {|t|
puts classify(nb, t)
}
end
main(ARGV)
実行
% ruby shatiku.rb kurage.2.txt jkondo.2.txt 興味ないね => 社畜 エアリスはもう喋らない・・・笑わない・・・泣かない、怒らない・・・! => 社畜 大切じゃない物なんか無い! => 社畜 俺は俺の現実を生きる => 社畜 俺は、お前の生きた証だ => 社畜 指先がチリチリする。口の中はカラカラだ。目の奥が熱いんだ! => 社畜 オレが・・・お前の生きた証・・・ => 社畜 引きずりすぎて少しすり減ったかな・・・ => 人間 お前の分まで生きよう。そう決めたんだけどな… => 社畜 もう・・・揺るがないさ・・ => 社畜 帰るぞ => 社畜 俺は幻想の世界の住人だった。でも、もう幻想はいらない……俺は俺の現実を生きる => 社畜 ここに女装に必要な何かがある。おれにはわかるんだ。いくぜ! => 人間 星よ・・・降り注げ!! => 社畜 罪って…許されるのかな? => 社畜 まだ終わりじゃない…終わりじゃないんだ! => 人間 俺はクラウド、ソルジャークラス1st => 社畜
ふむ。
2013-06-12 :-(
2013-06-13 :-(
_ 午後
1300 ガジェット
_ ,
アイカツ カードリスト 第5弾 のプレミアムレアは、アニメ34話で使われたカードでありますか。
_ ,
「すげえ。ぬるぬる動いてるじゃん」という話題になったんだが、アイドルマスターで培った技術でしょうかナムコさん。
_ 声優内海賢二さん死去「アラレちゃん」則巻千兵衛「北斗の拳」ラオウ ― スポニチ Sponichi Annex 芸能
アニメ「北斗の拳」のラオウ役として知られる声優の内海賢二(うつみ・けんじ、本名健司=けんじ)さんが13日午後3時1分、がん性腹膜炎のため東京都新宿区の病院で死去した。75歳。北九州市出身。
ご冥福をお祈りします。
賢プロダクション (内海賢二 会長)の賢プロおもちゃ箱に行ったのが 2006 年なのだなあ [ 20061203#p08 ]。
2013-06-14 :-(
_ 午後
1300 ガジェット
_ ,
Twitter を眺めているとソウルジェムが濁ってくるので tumblr に避難する。tumblr は最後のユートピアである。
_ 膝サポーターのマジックテープが張り付かなくなった
以前買った ZAMST の膝サポーター [ 20121112#p04 ] なのだが、吸着される側がもうアレされている。
寿命は半年のようだ。1 年間もたないのか。
半年で 6000 円(両足なのでx2) として、1 年間で 12000 円になるかなあ。うーん
_ ,
「ソシャゲの課金手法は、ゲーセンでコインを積んで修行してたのと同じなので」ってばっちゃが言ってた。
2013-06-15 :-)


_ 扇風機始動!

_ [バイナリ][比較][diff][winmerge]バイナリファイルを比較する
環境
- Microsoft Windows 7 (64bit)
- cygwin
- WinMerge
バイナリ比較
バイナリファイルを比較したい。(バイナリってなんだよ。可視化できないファイルですか?)
Windows の環境なのでテキトーにググるなどしたんだけど見つからない。
Stirling
Stirling ( Stirling ) を使って以下のように「ダンプイメージの保存」することによってテキストファイルとして保存すればテキストファイルを比較できるようになるんだけど、いちいち 2, 3 ステップの手間がかかるので手間を省きたいものの、「ダンプイメージの保存」がどうもコマンドラインから使う方法が分からない。ヘルプにも無い。そもそもコマンドラインから使えるのか分からない(ファイルを開くことくらいはできた)。
ADDRESS 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 0123456789ABCDEF ------------------------------------------------------------------------------ 00000000 42 4D 36 05 00 00 00 00 00 00 36 04 00 00 28 00 BM6.......6...(. 00000010 00 00 10 00 00 00 10 00 00 00 01 00 08 00 00 00 ................ 00000020 00 00 00 00 00 00 13 0B 00 00 13 0B 00 00 00 01 ................ 00000030 00 00 00 01 00 00 FF FF FF FF C0 C0 C0 FF FF 00 ..........タタタ... 00000040 00 FF 00 FF 00 FF FF FF 00 FF 00 00 FF FF FF 00 ................ 00000050 FF FF 00 FF FF FF F0 F0 F0 FF E0 E0 E0 FF D0 D0 ........珥..ミミ 00000060 D0 FF C0 C0 C0 FF B0 B0 B0 FF B0 B0 B0 FF 90 90 ミ.タタタ.ーーー.ーーー.瑞 00000070 90 FF 80 80 80 FF 00 00 00 FF 80 80 80 FF 80 00 ................ 00000080 00 FF 00 80 00 FF 80 80 00 FF 00 00 80 FF 80 00 ................ 00000090 80 FF 00 80 80 FF 70 70 70 FF 60 60 60 FF 50 50 ......ppp.```.PP :
それ hexdump で出来るよ
書いた。
Windows のパス名と cygwin パス名が混在するので面倒くさい。chomp がダサいんですけど。
# coding: utf-8
require 'tempfile'
require 'pp'
def main(argv)
dumpcmd = "/usr/bin/hexdump -vC"
diffcmd = '/cygdrive/c/Program\ Files/WinMerge/WinMergeU.exe /x'
cygpathcmd = "/usr/bin/cygpath"
file1 = `#{cygpathcmd} -u "#{argv[0]}"`.chomp("\n")
file2 = `#{cygpathcmd} -u "#{argv[1]}"`.chomp("\n")
tmp1 = Tempfile::new(file1, "./")
tmp2 = Tempfile::new(file2, "./")
`#{dumpcmd} "#{file1}" > "#{tmp1.path}"`
`#{dumpcmd} "#{file2}" > "#{tmp2.path}"`
f1 = `#{cygpathcmd} -w "#{tmp1.path}"`.chomp("\n")
f2 = `#{cygpathcmd} -w "#{tmp2.path}"`.chomp("\n")
`#{diffcmd} "#{f1}" "#{f2}"`
end
main(ARGV)
こんなバッチファイルを用意する。
cd /d %~dp0 c:\cygwin\bin\ruby biff.rb %1 %2
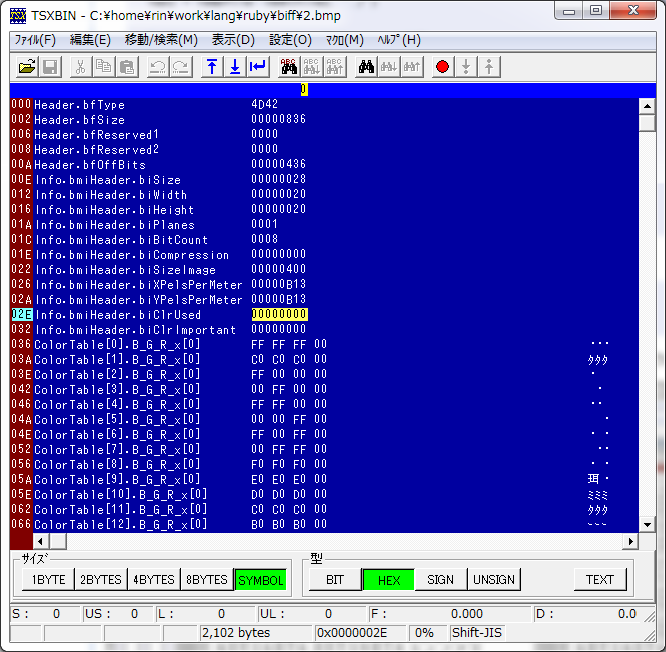
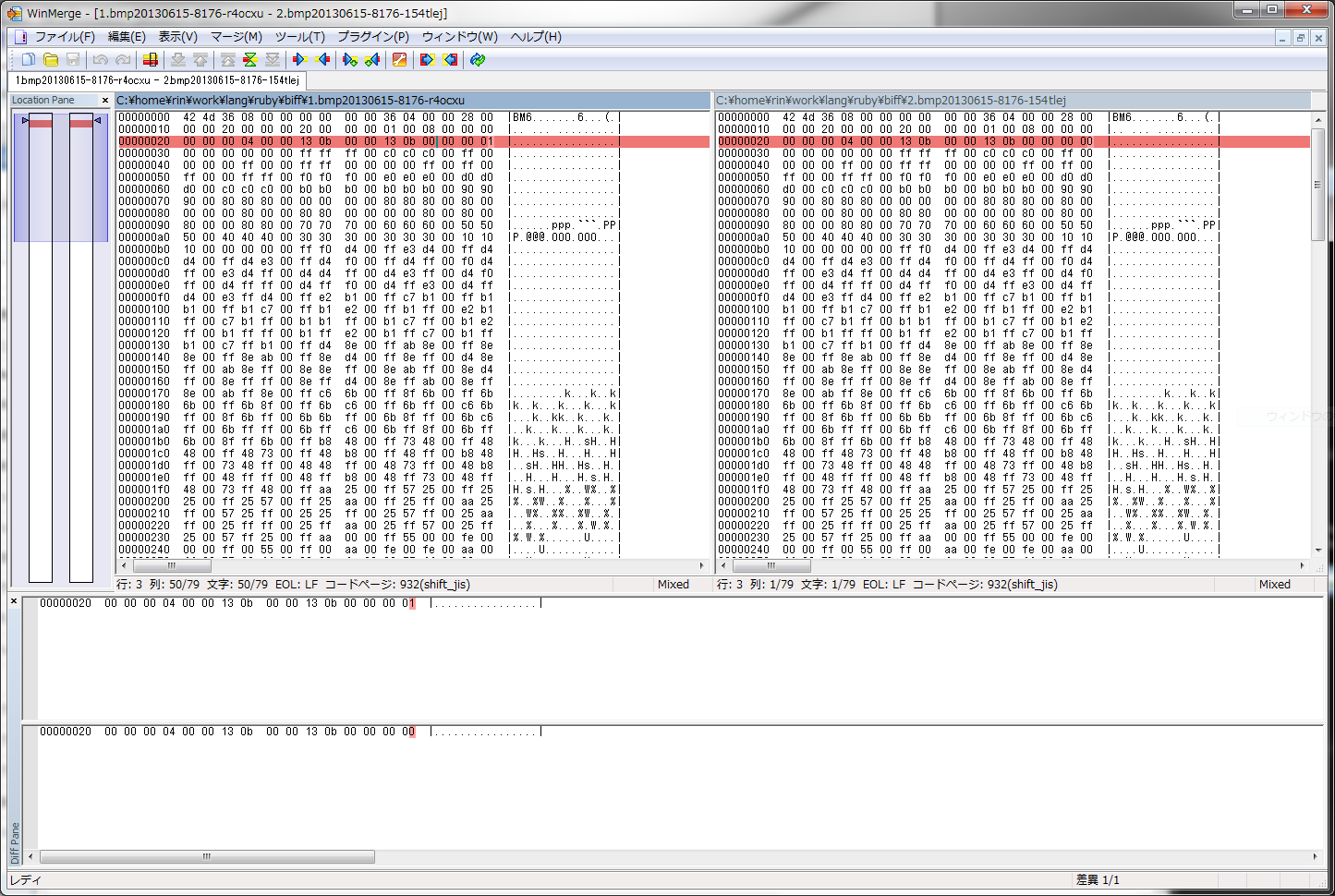
ためしにテキトーな Windows ビットマップファイルの ClrUsed を 100 から 000 に変更しておく。( TSXBIN を使うとビットマップファイルの要素ごとに編集できる。チョー便利 )
変更前と変更後のファイルを選択してドラッグドロップすると hexdump -C してから winmerge で比較するようになる。
_ [Twitter]Twitter クライアントとして Crowy を試してみる
Twitter API の 1.1 以降にともない、私がいままで使っていた P3 が死んだ( 【追記あり】P3:PeraPeraPrv finished its role. - とかいろいろ )。
代替を探そうとして、とりあえず自分のブクマを検索したら たださんの日記( TweetDeckが信じられない改悪をしてきたのでCrowyに乗り換え - ただのにっき(2011-12-12) ) へのブクマがヒットしたので Crowy を使ってみることにした。
ガチ製は TweetIrcGateway とか使ってるんだろうけど、私はヘタレなので GUI を求めるのであった。
しばらく



2013-06-18 :-(
_ 午後
1300 ガジェット
_ 問1
このプログラムを 512KB の領域に収めるにはどうすればよいか。
_ 同僚が辞めるらしい(3)
その報告を聞いたときに最初に考えたのが「引継ぎは...大丈夫か」でした。「残念」「さびしくなる」などと考えませんでした。以前からまったく変わってないですね[ 20080414#p07 ]
2013-06-21 :-(
_ 午後
1300 ガジェット
_ [情報セキュリティスペシャリスト試験][情報処理技術者試験][IPA]ねんがんの 情報セキュリティスペシャリスト試験に ごうかくしたぞ
受験 4 回目にしてようやく合格した。
平成25年度 春期 情報セキュリティスペシャリスト試験 成績照会
| 午前I得点 | ***.**点 |
| 午前II得点 | 72.00点 |
| 午後I得点 | 72点 |
| 午後II得点 | 84点 |
(午前I免除)
「午後問題は国語が出来れば受かる」は本当だった。つまり問題文にヒントが散りばめられているので文脈解析できればよい。
過去 3 回はいつも午後IIで落ちていた(つまり 50 点くらい)。毎回問題文を流し読みしていたので、それを反省し、今回は本気で問題文の文脈解析につとめたところ、見事に合格した。しかも過去最高得点だ。
参考書
結局この 2 冊をひたすら読んでいた。前者で知識を網羅的に得て、後者で午後試験の練習する。そんだけ。
(2011 年に買ったので古いです)
4798122564
4798027669
参考にしなかった書
ポケットスタディも買ったけど、これは脈絡がないように見えて、読みづらかった。
4798028061
こちらは業務で ISMS などをやる場合は欲しい。けど試験勉強に使うには詳細すぎる。
4407316969
_ [C][バイト配列][整数][ポインタ]リハビリ (2)
ポインタとかよく分からない。
#include <stdio.h>
unsigned int toInt1(unsigned char* buf)
{
unsigned char* p;
unsigned int n = 0;
p = (unsigned char*)&n;
p[0] = buf[0];
p[1] = buf[1];
p[2] = buf[2];
p[3] = buf[3];
return n;
}
unsigned int toInt2(unsigned char* buf)
{
unsigned int n = 0;
n = (buf[3] << 24) | (buf[2] << 16) | (buf[1] << 8) | (buf[0]);
return n;
}
unsigned int toInt3(unsigned char* buf)
{
unsigned int n = 0;
n += buf[3] << 24;
n += buf[2] << 16;
n += buf[1] << 8;
n += buf[0];
return n;
}
int main(int ac, char** av)
{
unsigned char buf[4] = {0xAB, 0xCD, 0xEF, 0x01};
printf("0x%X\n", toInt1(buf));
printf("0x%X\n", toInt2(buf));
printf("0x%X\n", toInt3(buf));
return 0;
}
% gcc byte0.c % ./a.exe 0x1EFCDAB 0x1EFCDAB 0x1EFCDAB



2013-06-23 :-)


_ [gcc][文字列][string]gcc の string
gcc 4.5.3 i386
#include <stdio.h>
#define STR1 "HELLO"
#define STR2 "HELLO"
int main(int ac, char** av )
{
char* s1 = STR1;
char* s2 = STR2;
if(s1 == s2)
{
puts("match");
}
else
{
puts("unmatch");
}
return 0;
}
% gcc hello1.c % ./a.out match
アレ...? (;゚д゚)
アドレスを比較するので、unmatch になると思ったんだけど、違うのか。
たしかに rodata には "HELLO" が 1 つしかないから一緒くたにされてるようだ。へーへー
.file "hello1.c"
.section .rodata
.LC0:
.string "HELLO"
.LC1:
.string "match"
.LC2:
.string "unmatch"
.text
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
andl $-16, %esp
subl $32, %esp
movl $.LC0, 28(%esp)
movl $.LC0, 24(%esp)
movl 28(%esp), %eax
cmpl 24(%esp), %eax
jne .L2
movl $.LC1, (%esp)
call puts
jmp .L3
.L2:
movl $.LC2, (%esp)
call puts
.L3:
movl $0, %eax
leave
ret
.size main, .-main
.ident "GCC: (NetBSD nb2 20110806) 4.5.3"
_ [gcc][ARM][クロスコンパイル][クロスコンパイラ]gcc の ARM クロスコンパイル
環境
ホスト NetBSD 6.0 i386
gcc
いやほんとよく分からない。
gcc のマニュアルには「オプションあるよ」と書いてあるんだけど( ARM Options - Using the GNU Compiler Collection (GCC) ) -march すると怒られる。
% gcc -march=armv7 hello1.c hello1.c:1:0: error: bad value (armv7) for -march= switch
-march=i386 はエラーにならないので、gcc はターゲットごとにコンパイラを作らないといけないのかしら。
ググったら tsutsuii さんのスライド( NetBSD移植 いまむかし )にヒットしたのでとりあえず tools を作ってみる。
cd /usr/src
./build.sh -m evbarm tools
:
tooldir.NetBSD-6.0-i386/bin/nbmkubootimage
===> Tools built to /usr/src/obj/tooldir.NetBSD-6.0-i386
===> build.sh ended: Sun Jun 23 13:43:44 JST 2013
===> Summary of results:
build.sh command: ./build.sh -m evbarm tools
build.sh started: Sun Jun 23 13:30:41 JST 2013
NetBSD version: 6.0
MACHINE: evbarm
MACHINE_ARCH: arm
Build platform: NetBSD 6.0 i386
HOST_SH: /bin/sh
TOOLDIR path: /usr/src/obj/tooldir.NetBSD-6.0-i386
DESTDIR path: /usr/src/obj/destdir.evbarm
RELEASEDIR path: /usr/src/obj/releasedir
Updated makewrapper: /usr/src/obj/tooldir.NetBSD-6.0-i386/bin/nbmake-evbarm
Tools built to /usr/src/obj/tooldir.NetBSD-6.0-i386
build.sh ended: Sun Jun 23 13:43:44 JST 2013
===> .
とりあえずコンパイルしようとしたら怒られた。リンクできねーよ! と。ですよねー
% /usr/src/obj/tooldir.NetBSD-6.0-i386/bin/arm--netbsdelf-gcc hello1.c /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find crt0.o: No such file or directory /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find crtbegin.o: No such file or directory /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find -lgcc /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find -lgcc_s /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find -lc /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find -lgcc /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find -lgcc_s /usr/obj/tooldir.NetBSD-6.0-i386/bin/../lib/gcc/arm--netbsdelf/4.5.3/../../../../arm--netbsdelf/bin/ld: cannot find crtend.o: No such file or directory collect2: ld returned 1 exit status
日本のどこかに ARM 用の crt0 を待っているひとがいるかもしれないんだけどよく分からないから ./build.sh build までやって、どうやってるのか眺めてみることにした。
cd /usr/src ./build.sh -m evbarm build
待つこと 2, 3 時間。
こんな行を見つけた( 長いので空白を改行に置換 )
/usr/src/obj/tooldir.NetBSD-6.0-i386/bin/arm--netbsdelf-gcc --sysroot=/usr/src/obj/destdir.evbarm -nostdlib -r -Wl,-dc -o sh.ro alias.o cd.o echo.o error.o eval.o exec.o ex pand.o histedit.o input.o jobs.o mail.o main.o memalloc.o miscbltin.o mystring.o options.o parser.o redir.o show.o trap.o output.o var.o test.o kill.o syntax.o arith.o arith _lex.o builtins.o init.o nodes.o printf.o
ARM
つまりこうすりゃいいらしい。
/usr/src/obj/tooldir.NetBSD-6.0-i386/bin/arm--netbsdelf-gcc --sysroot=/usr/src/obj/destdir.evbarm hello1.c
中身を見る。
file a.out a.out: ELF 32-bit LSB executable, ARM, version 1, dynamically linked (uses shared libs), for NetBSD 6.0, not stripped
ナルホディウス
_ Hello World!.s
ケッキョキ
なにがやりたかったかというと、ARM 向けにアセンブルすると何か変わるのかという。
align が追加されておる。( ref. データ型のアラインメントとは何か,なぜ必要なのか? )
.file "hello1.c"
.section .rodata
.align 2
.LC0:
.ascii "HELLO\000"
.align 2
.LC1:
.ascii "match\000"
.align 2
.LC2:
.ascii "unmatch\000"
.text
.align 2
.global main
.type main, %function
main:
@ args = 0, pretend = 0, frame = 16
@ frame_needed = 1, uses_anonymous_args = 0
mov ip, sp
stmfd sp!, {fp, ip, lr, pc}
sub fp, ip, #4
sub sp, sp, #16
str r0, [fp, #-24]
str r1, [fp, #-28]
ldr r3, .L4
str r3, [fp, #-16]
ldr r3, .L4
str r3, [fp, #-20]
ldr r2, [fp, #-16]
ldr r3, [fp, #-20]
cmp r2, r3
bne .L2
ldr r0, .L4+4
bl puts
b .L3
.L2:
ldr r0, .L4+8
bl puts
.L3:
mov r3, #0
mov r0, r3
sub sp, fp, #12
ldmfd sp, {fp, sp, pc}
.L5:
.align 2
.L4:
.word .LC0
.word .LC1
.word .LC2
.size main, .-main
.ident "GCC: (NetBSD nb2 20111202) 4.5.3"
2013-06-24 :-(
_ 午後
1300 ガジェット
_ [gcc]gcc のターゲット
それ configure で設定できるよ。
gcc 4.8.1
% ./configure --help : System types: --build=BUILD configure for building on BUILD [guessed] --host=HOST cross-compile to build programs to run on HOST [BUILD] --target=TARGET configure for building compilers for TARGET [HOST] :
% ./configure checking build system type... i686-pc-cygwin checking host system type... i686-pc-cygwin checking target system type... i686-pc-cygwin :
というわけで host と target は configure で指定されたりするのであった。
_ [田村ゆかり]今まで行った田村ゆかりのライブを思い出してみる - kariaの日記@Alice::Diary
そんなものなかった。
もはやメンテナンスしていない RIN's event list なるものがあるんだけど、ライブは行ってないけどイベントはちらほら行っていた。ような
実際のところ、膝に矢を受けてしまったのでスタンディングとかもはや無理であり 2F 席からまったり見るくらいしかできぬのであった。
卒業式だよ、全員集合!は 2 回まわしだったか。
| 1999/09/19 | 東京ゲームショー'99秋 | 野田順子 鳥井美沙 村井かずさ 田村ゆかり | 幕張メッセ |
| 2000/04/30 | Something Dreams マルチメディアカウントダウン5 周年記念イベント | 堀江由衣 田村ゆかり 椎名へきる 富永みーな | 国立代々木競技場第一体育館 |
| 2000/04/30 | やまとなでしこデビューイベント1000秒ライブ | 堀江由衣 田村ゆかり | 国立代々木競技場第一体育館 |
| 2000/12/10 | マイアミ☆ガンズ ビデオ&DVD発売記念イベント | 田村ゆかり 豊口めぐみ | 東京 TFTホール |
| 2001/03/10 | flower garden ファンクラブイベント | 堀江由衣 田村ゆかり | 東京原宿アストロホール |
| 2001/04/14 | ときめきメモリアル 2 プレミアムイベント | 野田順子 田村ゆかり 村井かずさ 野村真弓 くまいもとこ | 東京 杉並公会堂 |
| 2001/05/20 | 「ギャラクシーエンジェル」イベント | 新谷良子 田村ゆかり 沢城みゆき 山口眞弓 かないみか | 東京秋葉原ゲーマーズ本店 |
| 2001/12/02 | メモオフファーストコンサート | 山本麻里安 河合久美 那須めぐみ 間島淳司 田村ゆかり 浅野るり 利田優子 菊池志穂 池澤春菜 仲西環 千葉紗子 南里侑香 水樹奈々 KAORI | 東京新宿厚生年金会館 |
| 2002/01/13 | Kanon テレビアニメ化記念先行試写会 | 國府田マリ子 私市淳 田村ゆかり 川上とも子 皆口裕子 | 東京豊島公会開堂 |
| 2002/02/16 | 卒業式だよ、全員集合!~先生(?)人足りません~ | 野田順子 前田千亜紀 高野直子 村井かずさ 小菅真美 増田ゆき 鳥井美紗 本井えみ 田村ゆかり 橘ひかり | 東京 CLUB PHASE |
| 2002/02/16 | 卒業式だよ、全員集合!~先生(?)人足りません~ | 野田順子 前田千亜紀 高野直子 村井かずさ 小菅真美 増田ゆき 鳥井美紗 本井えみ 田村ゆかり 橘ひかり | 東京 CLUB PHASE |
2013-06-25 :-(
_ 午後
1300 ガジェット
_ [C]C
int a; a = 10; while (a != 10){ a = 10; // もしかしたら代入に失敗するかもしれない } これ実際に見たことあるコードです
— にゃおきゃっと (@nyaocat) May 14, 2013
#include <stdio.h>
int main(int ac, char** av)
{
int a = 10;
while(a != 10)
{
a = 10;
}
return 0;
}
普通に見てみる。
% gcc -S while0.c
.file "while0.c"
.def ___main; .scl 2; .type 32; .endef
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
pushl %ebp
movl %esp, %ebp
andl $-16, %esp
subl $16, %esp
call ___main
movl $10, 12(%esp)
jmp L2
L3:
movl $10, 12(%esp)
L2:
cmpl $10, 12(%esp)
jne L3
movl $0, %eax
leave
ret
最適化してみる。
% gcc -O3 -S while0.c
.file "while0.c"
.def ___main; .scl 2; .type 32; .endef
.text
.p2align 4,,15
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
pushl %ebp
movl %esp, %ebp
andl $-16, %esp
call ___main
xorl %eax, %eax
movl %ebp, %esp
popl %ebp
ret
まあたしかに「代入」されてないような。
2013-06-27 :-(
_ 午後
1300 ガジェット
_ ,
Facebook を眺めていると SAN値が上がっていくけど、その点 tumblr ってすげえよな。最後まで虹画像たっぷりだもん。
_ ,
とはいうものの旦那の愚痴を流しているひとを眺めるのもまた一興ではあるんだけd
2013-06-29 :-)

2013-06-30 :-)



_ [ドキドキ!プリキュア]ドキドキ!プリキュア 22 話を見るなど
釘宮理恵はツンデレ少女やか鋼鉄鎧少年などは馴染みがあるんだが、キュアエースはかなり新鮮だった。エースさん、色気がありすぎる。

(via 【百合寝】『ドキドキ!プリキュア』22話、キュピロッパっと登場!愛の切り札キュアエース!! : 虹神速報-にじそく )



_ エモエモ [筋トレ…(´・ω・`)]
_ みわ [(´ω` )]